
티스토리 뷰
알고리즘

탐색 알고리즘의 종류들부터 알아보기 이전에 탐색 알고리즘들은 기본적으로 그래프라는 데이터를 이용할 때 자주 사용된다. 그래프 데이터란, 노드(Node = Vertex = 정점)와 엣지(Edge = 간선)로 이루어진 데이터 형태이다. 아마 몇몇 분들은 딥러닝 모델 중 GNN(Graph Neural Network) 이라는 것을 알고 계실 텐데, 이 GNN에서 말하는 Graph와 비슷한 형태이다. 이러한 데이터로 이루어진 문제를 해결할 때 DFS, BFS 알고리즘이 자주 사용된다.

어쨌거나 탐색 알고리즘은 위와 같이 그래프 데이터일 때 자주 사용된다. 그런데 컴퓨터는 위와 같은 그림 형태의 데이터를 인식하지 못하고 숫자로 이야기를 해주어야 한다. 어떻게 나타낼까? 크게 2가지 방법으로 나타낼 수 있다. 먼저 인접 행렬(Adjacency Matrix)로 나타낼 수 있다. 인접 행렬은 우리가 고등학교 수학 시간에 배웠던 적이 있어 어렴풋이 기억이 날 수 있을 것이다.

이러한 인접 행렬을 '코딩 테스트' 차원에서 바라보자면 메모리 측면에서 비효율적이게 된다. 왜냐하면 중간 중간 0값이 존재하는 즉, 서로 연결되어 있지 않는 노드들 간의 관계까지 설명하고 있기 때문이다. 하지만 이것이 장점이 될 때도 있다. 어떤 특정한 두 노드들 간의 연결 유무를 파악할 때는 바로 밑에서 소개할 인접 리스트 방식 보다는 효율적이다.
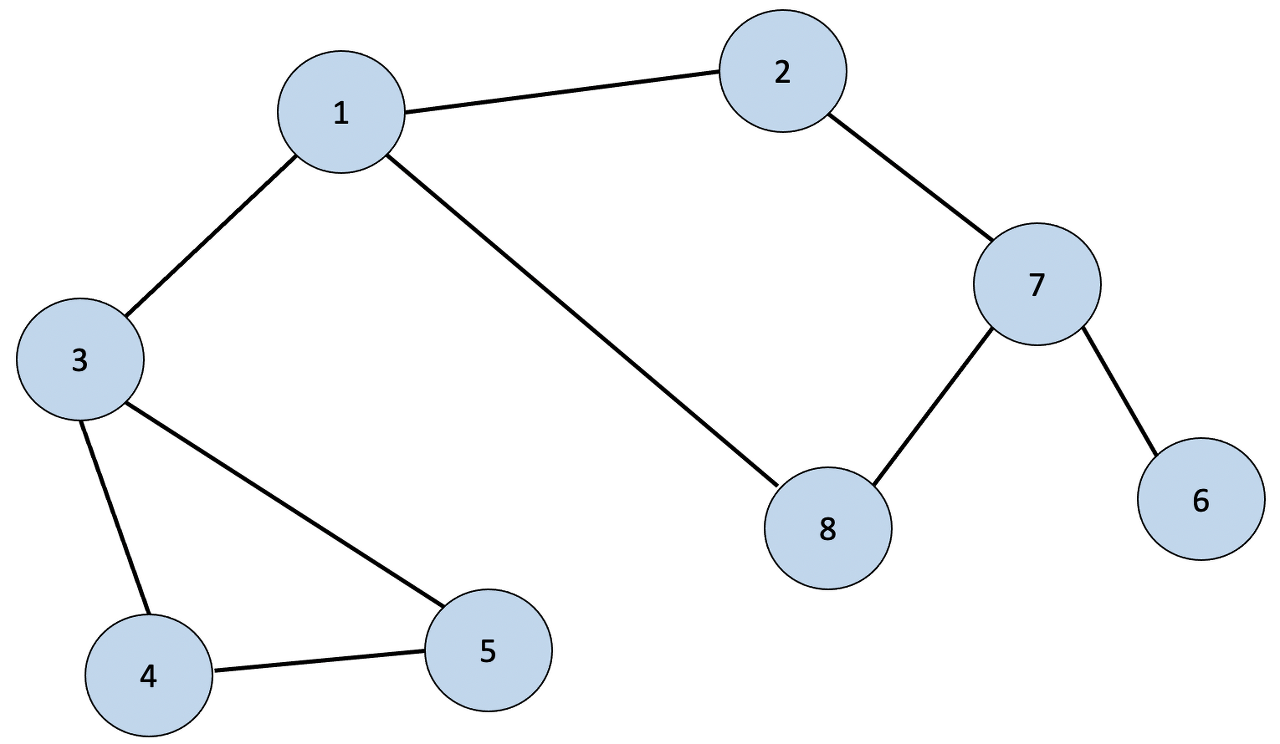
그렇다면 인접 리스트 방식은 무엇일까? 바로 노드들 간의 인접한 정보를 Python의 이중 리스트로 나타낸 것을 의미한다. 다음 그림을 살펴보자.

위 그림의 왼쪽인 그래프 형태의 데이터를 인접 리스트 방식으로 변형한다면 오른쪽과 같아진다. 빨간색 글씨로 되어 있는 부분은 두 노드 간의 간선에 부여된 값을 의미한다. 여기서는 간선에 부여된 값은 중요하지 않고 오른쪽의 인접 리스트 형태를 Python 리스트 자료구조로 변환하면 다음과 같아진다.
탐색 알고리즘
DFS(Depth-First-Search)
깊이 우선 탐색 알고리즘이라고도 한다. 이름 그대로 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다. DFS는 스택이라는 자료구조를 활용해서 구현된다. 스택 자료구조는 FILO(First-In-Last-Out) 방식을 따른다. 즉, 스택에 데이터를 집어넣을 때 순서와 스택에서 데이터를 꺼낼 때 순서가 역방향이라는 것이다. 다음 그림을 보면 이해가 수월할 것이다.

DFS 알고리즘은 특정한 경로를 탐색하다가 특정한 상황에서 최대한 깊숙이 들어가서 노드를 방문한 후 다시 돌아가 다른 경로를 탐색하는 알고리즘이다. 이 때 경로를 탐색하다 동일한 깊이의 인접한 노드가 여러개 있다면 이 중 노드의 번호가 작은 것부터 차례대로 탐색하는 것이 관행이라고도 한다.
그렇다면 이 DFS 알고리즘을 Python으로 어떻게 구현할까? 주목할 만한 점은 재귀함수를 사용한다는 것이다. 최대한 '깊게' 탐색하는 것이기 때문에 인접한 노드의 인접한 노드의 인접한... 이런 식으로 진행되기 때문에 재귀함수를 사용하게 된다. 다음과 같은 그래프 데이터가 있다고 가정하고 Python으로 DFS를 구현해보자.

BFS(Breadth-First-Search)
너비 우선 탐색 알고리즘이라고도 한다. 너비 우선 탐색은 가장 가까운 노드부터 탐색하는 알고리즘이다.(이러한 측면에서 봤을 때 DFS는 최대한 깊은 부분을 탐색한다는 점에서 가장 멀리 있는 노드를 우선으로 탐색한다는 차이점이 있다.)
BFS는 큐라는 자료구조를 사용한다. 큐는 FIFO(First-In-First-Out) 방식을 사용한다. 즉, 큐에 데이터를 넣을 때 순서와 큐에서 데이터를 뺄 때 순서가 동일하다. 다음 그림을 살펴보자.

BFS도 만약 동일한 깊이의 노드가 여러개 있다면 큐에 노드에 새겨진 숫자가 작은 노드들 부터 삽입한다는 점을 알고있자. BFS가 동작하는 구체적인 프로세스도 나동빈님의 7분 강의를 참고하자.
이제 BFS도 Python으로 구현해보자. 큐를 사용해야 하는데 Python에서는 collections 라이브러리가 제공하는 deque 메소드를 사용하면 된다. DFS 구현 때와 동일하게 다음과 같은 그래프 데이터가 주어졌을 때 BFS를 Python으로 구현한 코드는 다음과 같다.
정렬 알고리즘
선택 정렬(Selection Sort)
개인적으로 생각하기에 단순 무식(?)한 정렬 방법인 것 같다. 무작위로 정렬된 데이터가 있을 때, 가장 작은 데이터를 선별해 가장 앞의 인덱스 위치에 놓고 그 다음으로 작은 데이터를 선별해 두 번째 인덱스 위치에 놓고... 계속적으로 하여 N-1번 반복하는 알고리즘이다. 그림으로 표현하면 다음과 같다.

삽입 정렬(Insertion Sort)
삽입 정렬의 아이디어는 데이터를 하나씩 확인하면서 그 데이터의 적절한 위치에 삽입해보자는 것에서 유래했다. 삽입 정렬의 주요한 특징은 주어진 데이터의 가장 첫 번째에 위치한 데이터는 정렬되었다고 가정하고 시작을 한다. 따라서 두 번째 위치에 있는 데이터부터 하나씩 확인해보면서 왼쪽에 있는 데이터와 비교를 해서 왼쪽에 있는 데이터보다 작다면 왼쪽으로 계속 이동하고 크다면 그 자리에 그대로 두는 로직으로 구성된다. 이러한 로직으로 구성되면 비교를 점차적으로 하면서 왼쪽에 있는 데이터들은 항상 오름차순을 유지하게 된다.

퀵 정렬(Quick Sort)
퀵 정렬은 알고리즘 종류 중 가장 많이 사용되는 알고리즘 중 하나이다. 퀵 정렬과 비슷한 유형으로 병합 정렬 알고리즘이 있는데, 이 병합 정렬은 Python 정렬 라이브러리를 구현할 때 사용된 알고리즘이라고 한다.
퀵 정렬은 기준 데이터를 설정하고 그 기준보다 큰 데이터, 작은 데이터의 위치를 바꾸는 아이디어에서 출발했다. 이 때 기준 데이터를 피벗(Pivot)이라고 한다. 피벗을 정하는 기준에 여러가지가 있지만 여기서는 호어 분할 방식의 기준으로 하여 데이터의 가장 첫 번째 요소를 피벗으로 설정하도록 한다.
피벗 데이터를 선정하고 왼쪽 방향부터 시작해 차례차례 데이터를 확인해가면서 피벗 데이터 값보다 큰 데이터 값이 첫 번째로 등장한 데이터를 지정한다. 반대로 오른쪽 방향(데이터 끝에서)으로 차례차례 데이터를 확인해가면서 피벗 데이터보다 작은 데이터 값이 첫 번째로 등장한 데이터를 지정한다. 그리고 이 두개의 위치를 교환한다.
이런 과정을 반복하다가 두개의 데이터 위치 index가 엇갈릴 경우 피벗보다 작은 값으로 처음 등장한 데이터와 피벗 데이터와 위치를 교환한다. 그리고 피벗의 바뀐 위치를 기준으로 양 옆으로 '분할(파티션이라고도 함)'해 만들어진 2개의 리스트에서 각각 퀵 정렬을 또 수행한다. 텍스트로 이해가 잘 안된다면 하단의 그림을 참고하자.

계수 정렬(Counting Sort)
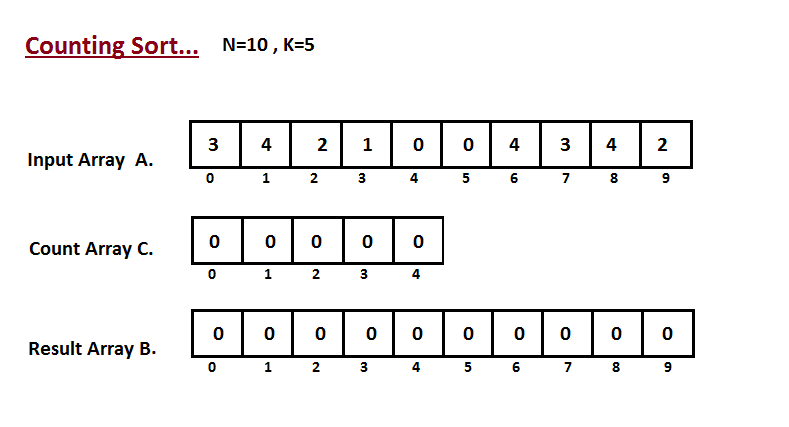
계수 정렬은 특정한 조건이 부합할 때만 사용할 수 있지만, 그 조건을 만족할 경우 사용하면 매우 빠른 정렬 알고리즘이다. 그 조건이라 함은 바로 제한된 크기 범위의 정수 형태로 데이터가 주어질 경우에만 사용할 수 있다는 것이다. 그리고 가장 큰 데이터와 가장 작은 데이터의 차이가 백만(1,000,000)을 넘지 않을 때 효과적으로 사용할 수 있고 중복된 데이터가 여러개 나타날 경우에도 적절히 사용될 수 있다.
그리고 계수 정렬을 사용할 때 주목할 만한 점은 주어진 데이터의 모든 범위를 담을 수 있는 크기의 빈 리스트를 먼저 정의해야 한다는 것이다. 그리고 이름에서 알 수 있다 시피 Count 즉, 빈 리스트에 데이터의 값들이 몇 번 발생했는지 횟수를 기록한다. 다음 그림을 살펴보자.
'TIL WIL' 카테고리의 다른 글
| 항해 99 TIL-18 앨런 매시슨 튜링 (0) | 2022.02.23 |
|---|---|
| 항해 99 TIL-17 자료구조 (0) | 2022.02.22 |
| [WIL-6week] 2021.02.14~02.20 (0) | 2022.02.20 |
| 항해 99 TIL-15 프로그래밍의 기본 : 문장과 함수 (0) | 2022.02.19 |
| 항해 99 TIL-14 최초의 프로그래밍 언어 (0) | 2022.02.18 |
